当 Codex 会做却总做不完:我怎么把一条总会停下来的任务,改成可续跑的 workflow
为什么 AI 会做的任务却总是做不完?这篇文章分享如何把一个容易中断的 Codex 任务,改造成一个可持续推进的 workflow。
这次把我逼停的,不是识图效果。
而是一条明明已经能跑起来的任务,跑着跑着就停了。
我在做一件很具体的事:把系统里已经存在的大量图片稳定地过一遍图像理解,再把结果写进一个单独的 AI 元数据库,给后面的文章级 AI 汇总做底层材料。
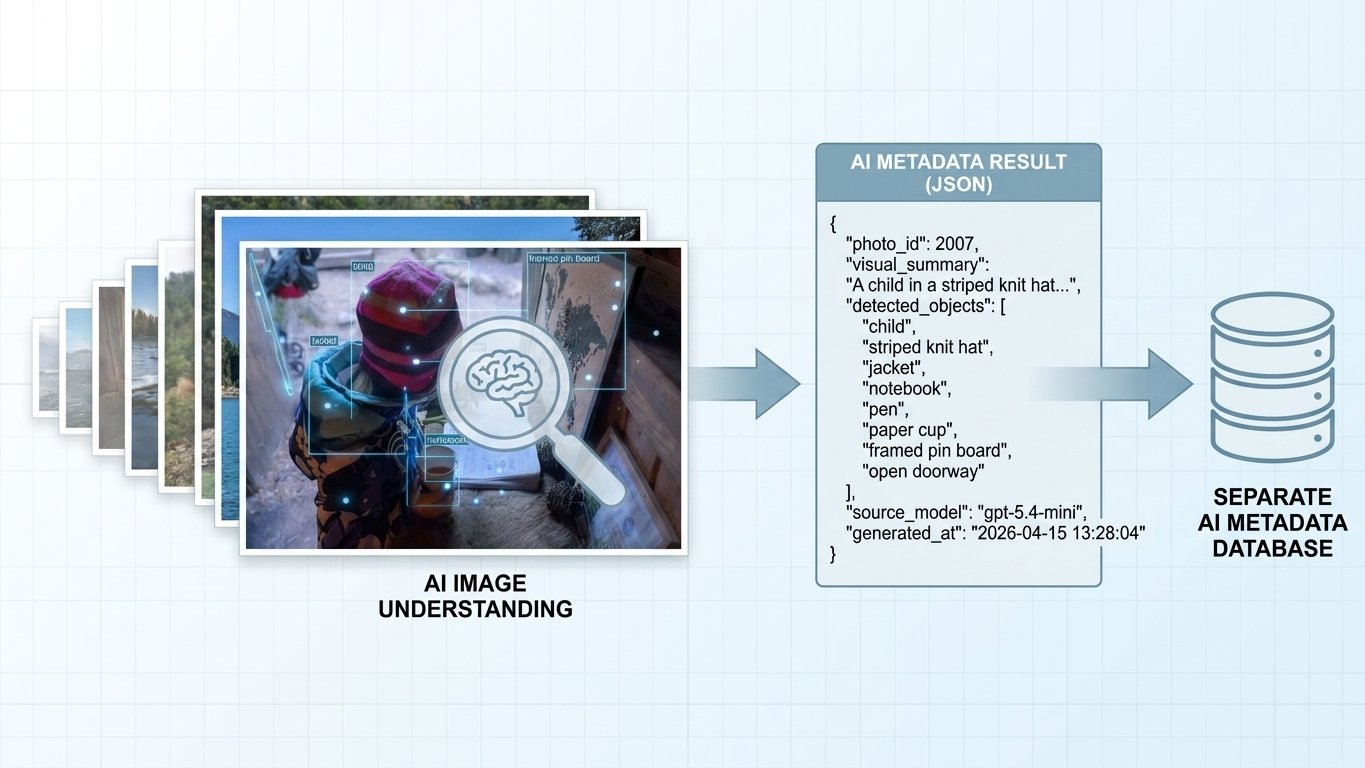
前面拿几张图试的时候,几乎没什么问题。Codex 能看图,也能回结果。
但量一上来,问题马上变了味。它会做,但只做一段就停。可能是 5 分钟,也可能是 10 分钟。系统看着还在工作,实际上 backlog 并没有稳定往前走,很多时候还得我再补一句,让它继续。
我后来才确认,卡住的不是识图。
卡住的是推进。
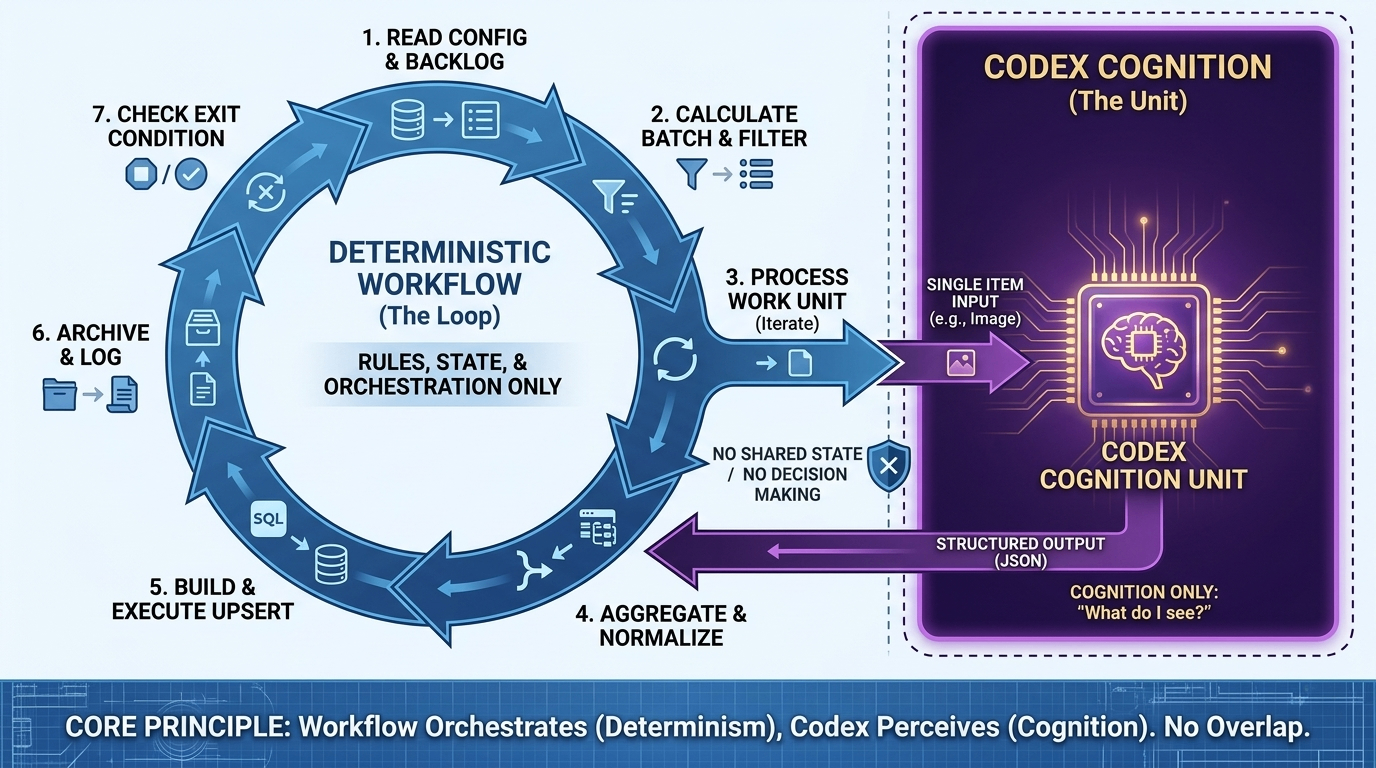
这篇文章我想讲清楚的,就是我是怎么把这件事从“让 Codex 直接扛完整条长任务”,改成“让 workflow 负责编排,Codex 只做最小认知单元”的。改完以后,这条链路才真正变成了一个能继续跑、能停、能续跑、能审计的 loop。
真正的问题
如果只看功能描述,这件事很像一句简单的话:
“把没处理过的图片交给模型看一下,再把结果写回去。”
但真正落到系统层面,我需要它满足的是另外几件事:
- 每个输入最终都会被处理到
- 成功和失败都要留下记录
- 任务可以中断,也可以继续跑
- backlog 能自己往前推进
- 跑完以后,系统自己知道该停
到这一步我才意识到,这已经不是一个“prompt 写得够不够好”的问题了。
它是一条执行链路。
最早的错误
我一开始的想法其实很直接。
既然 Codex 能读图、能调工具、能写代码,那干脆把整条任务都交给它。
我当时让它同时负责:
- 查哪些数据还没处理
- 切 batch
- 拉远程资源
- 组织回传结果
- 生成写入内容
- 回写数据库
- 决定要不要继续下一轮
这么做一开始看起来当然更省事。
因为如果模型足够强,最偷懒的做法当然就是一句话:
“把这批事情做完。”
真正跑起来以后,我开始慢慢不信它。
它没有总是报出一个很响亮的错。更麻烦的是,一旦结果不对,你很快就失去定位问题的能力。你搞不清是模型理解歪了,是工具调用出错了,还是整个执行过程已经偏掉了。
更麻烦的是,这种方式对我来说几乎是黑盒。
它确实能开始做事,但更像是在完成一段对话,或者处理一个范围有限的子问题。只要任务开始拉长,开始有 backlog,开始要求它维护整条链路的推进状态,它就不稳定了。
后来我回头看,发现问题不神秘。
我只是把三件本来不该混在一起的事,硬塞给了同一个执行体:
- 看图和理解内容
- 调工具、读写数据
- 维护进度、重试和停机
只要这三层不拆开,系统迟早会变脆。
把 loop 拿回来
真正起作用的改动,其实就一句话:
workflow 负责编排,Codex 只负责认知
我后面所有调整,都是围着这句话展开的。
具体一点说,就是这些边界:
- 外层 loop 用确定性代码控制
- 模型只处理一个最小工作单元
- 规则判断写回代码
- 状态推进也写回代码
从那以后,我不再让 Codex 决定下一步跑什么,也不再让它维护全局状态,更不再指望它自己把 backlog 从头推到尾。
我只让它回答一个它本来就擅长的问题:
“我看到了什么?”
边界一清楚,系统立刻安静很多。
最后的结构
我后来留下来的,不是一个“大 Agent”,而是一套拆开的文件。
核心结构大概是这样:
scripts/loop/
README.md
item_ai/
README.md
run_loop.sh
single_item.prompt.md
result.schema.json
build_upsert_sql.mjs
.logs/
关键不在目录长什么样,而是谁负责什么:
run_loop.sh负责外层推进single_item.prompt.md只处理一个 work unitresult.schema.json约束输出结构build_upsert_sql.mjs把结果转成真正可写入的内容
我后来越来越喜欢这种拆法。因为你一眼就能看清楚哪一层出了问题,而不是把所有控制都堆在 prompt 里。
我怎么把它拆稳
第一刀:先把任务压回最小 work unit
以前我交给 Codex 的任务是:
“把这条链路跑完。”
后来我交给它的任务变成了:
“处理一个输入,返回一个结构化结果。”
如果输入是一张图,它要做的就只有这些:
- 读取图片
- 描述真实可见内容
- 返回结构化 JSON
而不是顺便决定:
- 这张图属不属于当前 batch
- 这轮是不是最后一轮
- 失败后要不要重试
- 什么时候该写库
这一刀切下去之后,系统复杂度一下就掉了。
模型不再管整条任务,只管一个 work unit。
第二刀:外层 workflow 只做确定性工作
外层脚本我后来收得很窄。
它只负责这些事:
- 读取配置
- 查询 backlog
- 计算 batch
- 做规则过滤
- 逐个调用 Codex
- 聚合结果
- 生成写入内容
- 回写存储
- 归档
- 判断是否继续下一轮
这一层不需要聪明。
它需要的是可预测。
因为系统能长期跑,不靠“智能”,靠的是这些更硬的东西:
- 当前状态能看见
- 边界清楚
- 失败可以恢复
- 退出条件明确
第三刀:规则判断全部写回代码
后来我给自己定了一条很硬的规则:
凡是规则问题,都别交给模型。
比如:
- 某个输入该不该处理
- 某个来源合不合规
- 某种情况该跳过还是记失败
- 失败后应该落成什么状态
这些都应该回到确定性逻辑里。
模型应该只回答它擅长的那部分,也就是认知问题。
规则一旦也丢给模型,系统马上又会变吵。
第四刀:每个 work unit 都落独立结果
这层对我后面的排错帮助非常大。
每处理一个输入,workflow 都会落一份独立结果文件。最简单的时候,长这样就够了:
{
"item_id": 1932,
"status": "done",
"summary": "...",
"error": ""
}
它同时承担两件事:
- 机器可读状态
- 人类可审查记录
很多 AI workflow 也会记日志,但日志往往不落在真正的工作单元上。
而一个 item 一份结果文件的好处是,你随便打开一条记录,马上就知道:
- 处理对象是谁
- 当前状态是什么
- 输出长什么样
- 有没有错误
这比单纯看一串日志好用得多。
第五刀:写库前再做一层统一归一化
我没有把模型结果直接写回数据库。
中间一定还要过一层统一归一化。
例如由主线程补齐这些字段:
source_modelsource_versionreview_statusupdated_at
这一层的价值不在于“多做一步”,而在于写入结构最终还是由系统控制,而不是模型返回什么就吃什么。
这会直接影响你后面查数据、改字段、做版本迁移时的可维护性。
第六刀:让系统自己知道什么时候该停
真正的 workflow 不是“多跑几轮看看”。
它必须有明确的退出条件。
我最后保留的停机判断很简单:
- backlog 清空
- 当前 batch 为空
- 本轮没有推进 processed count
- 连续 stalled 超过上限
- 超过最大轮数
如果没有这些条件,系统就还是得靠人盯。
那它就不是 workflow,只是一个更长一点的手工过程。
跑完后怎么验证
我后来不太相信“命令没报错”这件事了。
判断这条 loop 有没有真的跑顺,我至少会看四层。
1. 处理计数有没有前进
最起码你要有两个明确数字:
- 总量
- 已处理量
例如某次 run 的状态如果是:
- 运行前:
366 / 786 - 运行后:
370 / 786
那我就知道,这一轮确实推进了 4 条。
这种数字比“感觉它跑了挺久”有用得多。
2. 每个 work unit 的结果是不是都落出来了
我至少会检查:
- 结果文件
- 原始模型输出
- 执行日志
如果输入本身需要先下载,还要确认本地落地有没有成功。
3. 存储层有没有真的被更新
这一步一定要查。
别只看本地结果,也别只看“SQL 已经生成了”。
真正的 source of truth 还是最后的存储层。
至少要核这些字段:
- 主键
- 结果字段
- 错误字段
- 模型来源
- 版本字段
- 状态字段
4. archive 和当前 run 目录是不是分层了
这一步很容易被忽略,但后面会直接影响维护体验。
理想状态是:
- 成功结果进 archive
- 调试现场留在当前 run 目录
这样以后回头看,你会有两种清楚的现场:
- archive 适合审结果
- 当前 run 目录适合排问题
这两类材料一旦混在一起,系统越大越难查。
Codex 适合做什么
这也是我这次特别确定的一点。
Codex 其实很适合帮我做 workflow 的第一版骨架。让它补脚本、补 schema、补目录、补说明文件,这些都很顺手。
但我不会再让它负责这些事:
- 长期推进 backlog
- 中断后的恢复
- 最终有没有跑完
所以 Codex 很适合帮你“写 workflow”。
但别把它本身当成 workflow。
这两个问题不是一回事。
我后来最顺手的做法,反而就是:
先让 Codex 帮我把第一版结构写出来,再由这条 workflow 自己一轮一轮去调用 Codex。
这样两种能力就分开了:
- 生成结构,交给模型
- 持续执行,交给系统
还没完全打透的地方
这篇文章讲的是已经跑通的 success path。
但我不想把它写成一种“所有失败分支都已经完全验证过”的口气。
至少还有两条路径,我觉得还值得额外做一次故障注入:
- 输入下载失败后,是否会稳定写成
error状态,并进入后续聚合 - 不合规输入是否会被正确跳过,同时留下可审计记录
系统里有这些分支,不等于这些分支就已经被认真压过了。
如果你要把这套模式搬到自己的任务里,我建议别只跑成功路径。额外做一次 fault injection,会更踏实。
最后
我这次收获最大的,不是“我让 AI 看懂了图片”。
而是我终于更确定了一件事:
当 Codex 明明会做,却总是做不完的时候,先别急着继续给它加 prompt、加上下文、加职责。
先把 loop 从它手里拿回来。
等编排重新回到系统里,整条链路反而会稳很多。
继续阅读
写芬兰、生活,也写代码。有新文章时,直接发到你的邮箱。
如果这篇文章对你有帮助,或者让你有新的想法,欢迎留言!